Menu
Close
Yolo model fine tuning
By Author • September 18, 2025
1. My Experience
Experience Fine-Tuning the YOLOv8 Classification Model for Car Brands
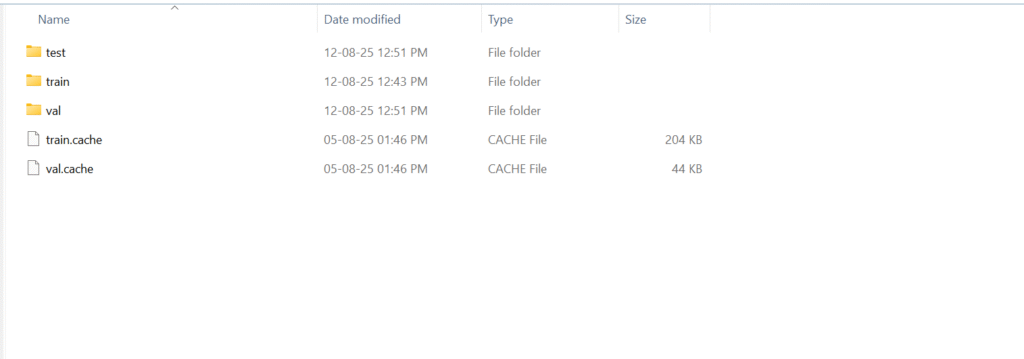
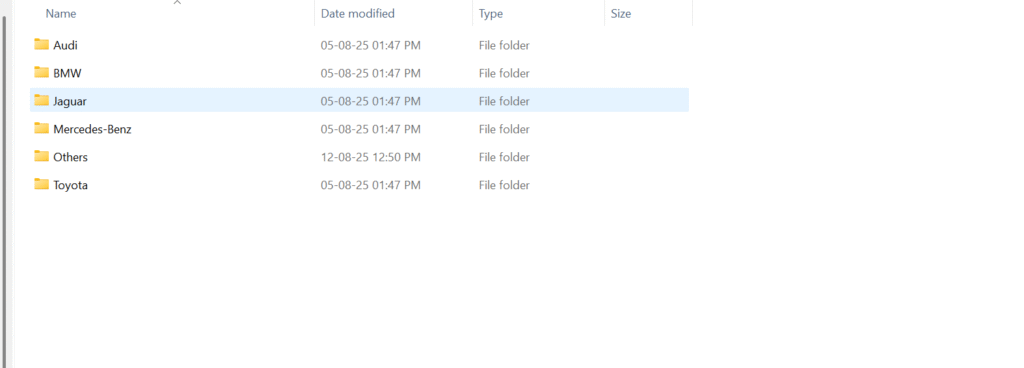
When I started fine-tuning, I realized how surprisingly simple YOLOv8 makes the classification process. Unlike many other models that require complex configuration files and detailed dataset annotations, YOLOv8 only needed a clean folder structure. I simply organized my dataset into five folders, each representing a car brand — BMW, Audi, Mercedes-Benz, Toyota, and Jaguar. With this setup, the model was able to automatically recognize the classes without requiring a custom YAML file. This simplicity not only saved me time but also made the entire fine-tuning workflow much more beginner-friendly and efficient.

Loading the pre-trained yolov8x-cls.pt model felt like a huge advantage in my fine-tuning process. Since the model was already trained on a massive dataset, it came with a strong understanding of general image features such as shapes, edges, and patterns. This meant I didn’t have to start from scratch, which saved me a lot of time and computation. Instead, I only needed to adjust the weights to make the model specialize in distinguishing my car brand classes. Transfer learning truly made the process more efficient and boosted accuracy with less training data.
At around 40 epochs, I started noticing the model showing early signs of improvement in recognizing the car brands. It was able to differentiate between classes to some extent, which indicated that the training was moving in the right direction. However, the predictions were not yet consistent or reliable enough for real-world use. The model still struggled with certain images, especially when the cars were at unusual angles or had background noise. This showed that the learning process was ongoing and the model hadn’t fully stabilized yet. By comparison, performance at 80 epochs was much clearer and more accurate.
I trained the model for a total of 80 epochs and closely observed how the accuracy graph changed over time. In the beginning, the model struggled to correctly classify the car brands, and the results were far from reliable. However, after the first few epochs, the accuracy graph showed a steady upward trend, indicating that the model was gradually learning. With each phase of training, it became better at picking up brand-specific features such as logos, grilles, and shapes. By the later epochs, its ability to differentiate between the car brands was noticeably stronger and more consistent.
2. Number plate detector (commercial or private or ev)
The batch size of 16 turned out to be the perfect balance during my training. Whenever I tried increasing it beyond that, I faced memory issues that slowed down the entire process or even caused interruptions. On the other hand, keeping the batch size too low made the training unnecessarily long and inefficient. With 16, everything ran smoothly on my system, ensuring faster training without compromising stability. This balance allowed me to progress steadily without hardware limitations holding me back.
Enabling augmentation (augment=True) was another key learning for me. Without it, I noticed the model was simply memorizing the training images, which led to poor generalization on unseen data. Once augmentation was enabled, the model was exposed to variations in images like flips, rotations, and lighting adjustments. This made it far more flexible in understanding real-world scenarios. As a result, its accuracy on test images improved noticeably, proving the importance of augmentation in classification tasks.
Through experimentation, I found that an image size of 224×224 worked best for this classification task. Using larger images increased the computational load significantly and slowed down the training process, which wasn’t practical. On the other hand, smaller sizes made the model miss important visual details, reducing accuracy. The 224×224 size provided the right balance between efficiency and performance, ensuring that training was fast while still capturing the fine details needed for accurate brand recognition.
One of the most exciting and motivating parts of the process was checking the training logs. Watching the accuracy and loss metrics evolve with every epoch gave me real-time feedback about the model’s learning progress. In the early stages, the values fluctuated a lot, but as training continued, the graphs stabilized and showed a steady upward trend. Seeing those improvements with each epoch gave me confidence that my efforts were paying off. It felt like the model was truly learning step by step.
I also came to understand the real value of checkpoints during training. There were times when my training environment faced interruptions or crashes, and without checkpoints, I would have had to restart everything from scratch. With them enabled, I could easily resume training from the last saved state without losing progress. This not only saved time but also reduced frustration, ensuring that my work was always secure. It taught me how crucial checkpoints are in long training sessions.
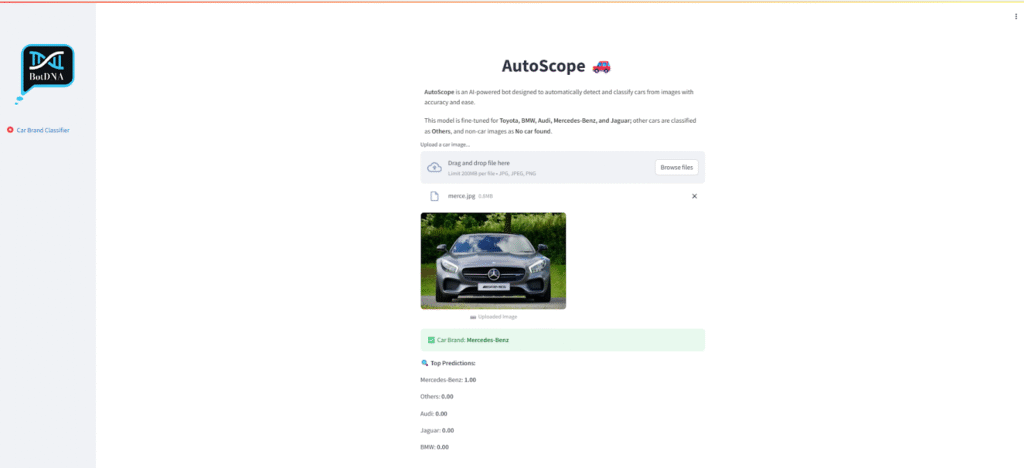
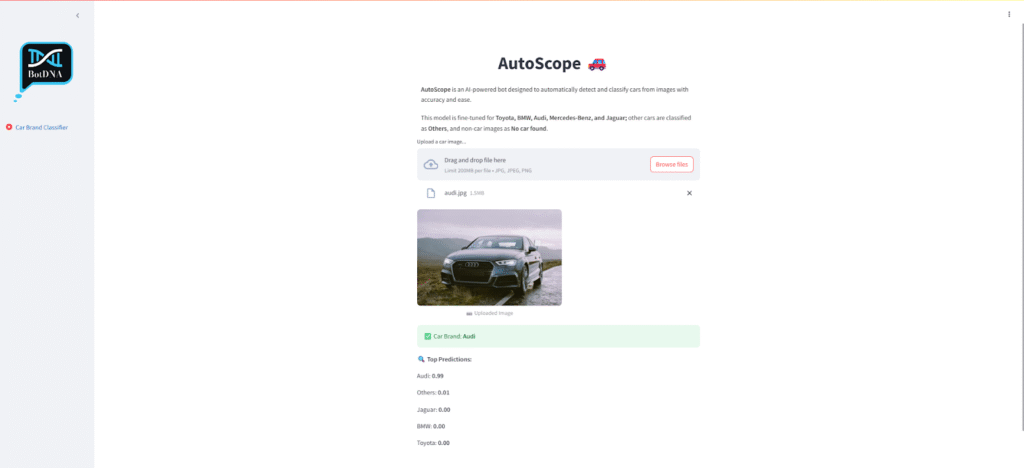
When I finally tested the model on unseen car images, the results were extremely satisfying. The model was able to distinguish between car brands like Audi and BMW with impressive accuracy. Even when the images came from different angles or had slightly cluttered backgrounds, the predictions were still reliable. This showed me that the training had genuinely helped the model learn brand-specific features. It was rewarding to see theory turn into practical, real-world results.
This entire fine-tuning process gave me valuable hands-on experience in model training and optimization. I not only learned about the technical aspects of YOLOv8 but also gained confidence in applying it to real-world scenarios. The fact that the model could scale to more car brands makes me optimistic about building even larger and more powerful applications. This experience strengthened my belief in YOLOv8’s potential for classification and opened up ideas for future projects.
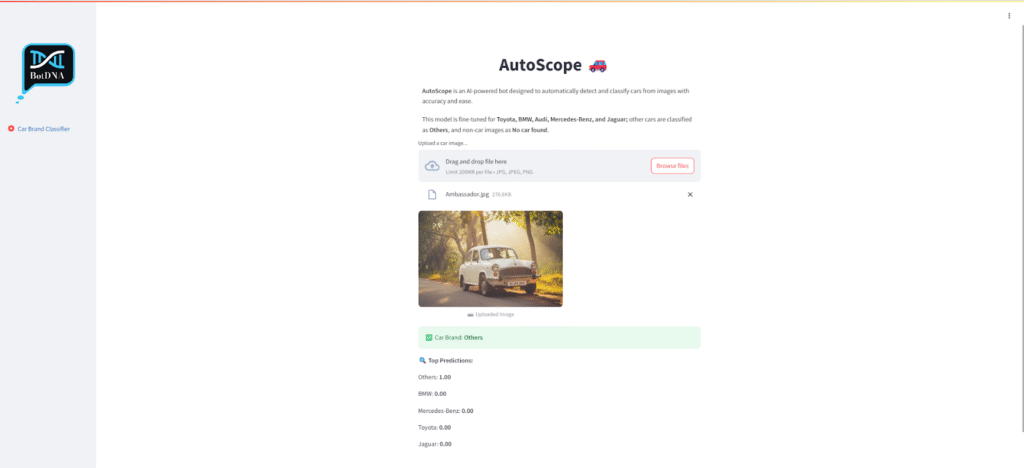
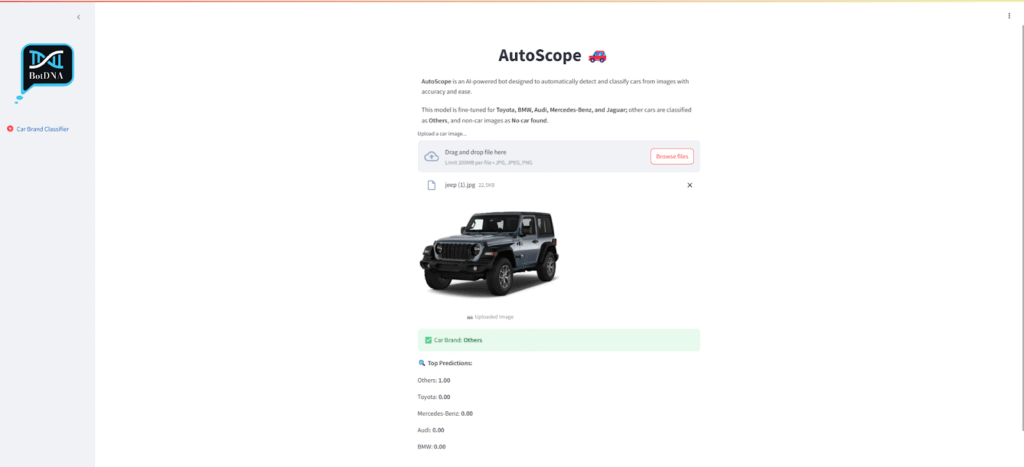
To make the model more practical and reliable, I decided to include an “Others” class. This class handled cars outside the main brands, preventing the model from misclassifying unknown cars as one of the trained classes. It added flexibility and made the model more realistic for deployment in everyday use cases. In real-world applications, you cannot always guarantee that cars will belong to a limited set of brands, so this addition significantly improved the model’s usefulness.