Menu
Close
1 YOLO Model Fine-Tuning
By Author • September 11, 2025
Table of Contents
- Introduction to YOLO
- Use Cases of YOLO
- Preparing the Custom Dataset
- Data Annotation and Preprocessing
- Environment Setup and Dependencies
- Fine-Tuning vs. Training from Scratch
- Common Issues During Training
- Deployment Options
- Personal Experience working with YOLO
Introduction to YOLO
Introduction to YOLO (You Only Look Once)
YOLO is a real-time object detection system that predicts bounding boxes and class probabilities in a single forward pass, framing detection as a regression problem. Introduced by Joseph Redmon in 2016, YOLO has evolved through multiple versions (YOLOv1–v8) and variants like YOLO-NAS and PP-YOLO.
Why YOLO Matters
Unlike traditional methods (R-CNN, Fast R-CNN, Faster R-CNN), YOLO is fast, efficient, and end-to-end, enabling real-time detection on edge devices. Applications include autonomous driving, surveillance, industrial inspection, medical imaging, AR, and retail analytics.
How YOLO Works (High-Level)
- Grid Division: Image divided into S × S grid.
- Bounding Box Prediction: Each grid predicts boxes with confidence scores.
- Class Prediction: Each grid predicts class probabilities.
- Final Output: High-confidence boxes are selected; duplicates removed via non-maximum suppression.
Use Cases of YOLO
YOLO Applications Across Domains
- Industrial Automation: Detect defects, count products, monitor machines — real-time, accurate in cluttered scenes.
- Autonomous Vehicles: Pedestrian/vehicle detection, traffic lights, lanes — low-latency, edge-device friendly.
- Traffic Monitoring: Vehicle counting/classification, incident detection — works with low-res footage, easy integration.
- Healthcare/Medical: Tumor/anomaly detection, cell counting — adaptable to medical datasets, fast processing.
- Security & Surveillance: Intruder/weapon detection, mask compliance — high FPS, suitable for edge deployment.
- Retail & Customer Analytics: People counting, shelf monitoring, shopper behavior — boosts efficiency, improves insights.
- Agriculture: Crop/pest detection, livestock monitoring — works with drone imagery, trainable on domain-specific data.
- Robotics: Object tracking, navigation assistance — real-time perception, hardware-embeddable.
- Augmented Reality (AR): Object labeling, gesture detection — interactive, low-latency UX.
- Environmental Monitoring: Wildlife, litter, pollution detection — works outdoors, supports drone/static feeds.
Preparing the Custom Dataset
YOLO Dataset Setup Detection
Structure:
dataset/
├─ images/{train,val,test}
└─ labels/{train,val,test}
- Each image ↔ matching .txt label.
- Splits: Train 70–80%, Val 10–20%, Test ~10%.
- Use scripts/Roboflow for balanced splits.
- data.yaml: defines train/val paths, nc, and names.
Classification
Organize by class:
dataset/train/{class}
dataset/val/{class}
- Labels inferred automatically, no data.yaml.
Data Annotation and Preprocessing
YOLO training starts with proper data annotation
- Draw bounding boxes, assign class IDs, and save in YOLO format:
<class_id> <x_center> <y_center> <width> <height> (all normalized 0–1, class_id starts at 0). - Use annotation tools (not manual editing).
- Dataset structure:
dataset/
├─ images/{train,val,test}
└─ labels/{train,val,test}
Each image must have a matching .txt label file.
Environment Setup and Dependencies
Hardware (recommended)
- GPU: NVIDIA ≥4 GB VRAM (8 GB+ for large models)
- RAM: 8–16 GB
- Storage: SSD
- OS: Ubuntu 18+, Windows 10/11, macOS (limited GPU)
- If no GPU → use Colab, Kaggle, or cloud GPUs (AWS/GCP/etc.).
Environment Options
- Local: full control, needs good GPU.
- Colab: free GPU, timeouts.
- Kaggle: free GPU/TPU, limited hours.
- Cloud GPU: scalable, paid.
Dependencies
- Python 3.8+
- PyTorch (GPU-enabled preferred)
- OpenCV
- YOLO repo (Ultralytics v5/v8, others)
- Extras: numpy, matplotlib, pandas, tqdm, PyYAML
Fine Tuning vs Training from scratch
YOLO Training Approaches
1. Fine-Tuning (Transfer Learning)
- Start from pre-trained weights (e.g., COCO).
- Best for small/medium datasets, similar classes.
- Faster, less data, higher accuracy, less overfitting.
- May carry dataset bias, not ideal for very different domains.
Example:
yolo task=detect mode=train model=yolov8s.pt data=data.yaml epochs=50 imgsz=640
2. Training from Scratch
Initialize with random weights.
- Best for very large datasets or unique domains.
- Learns domain-specific features, no bias.
- Needs huge data, more compute, longer training (hundreds of epochs).
Note : Fine-tune for most tasks; train from scratch only with massive or highly specialized datasets
Common Issues During Training
Common YOLO Training Pitfalls & Fixes
- Overfitting → Low val mAP, high train mAP.
Augmentation, fewer epochs, smaller model, early stopping. - Underfitting → High loss, low mAP everywhere.
More epochs, larger model, better data/labels. - Class Imbalance → Some classes ignored.
Collect more data, oversample/weight rare classes. - Labeling Errors → Misaligned boxes, wrong predictions.
Check format, match IDs with data.yaml, validate in CVAT/Roboflow. - Poor Convergence → Loss flat, mAP not improving.
Adjust LR, use pre-trained weights. - Over-augmentation → Model fails on clean images.
Keep augmentations realistic, preview them. - Incorrect Image Sizes → Missed small objects, slow training.
Use consistent size (e.g., 640×640). - Hardware Limits → Crashes, OOM errors.
Lower batch size, use smaller model, enable mixed precision.
Most issues come from data quality, hyperparameters, or hardware limits — fix those first before tweaking the model.
Deployment Options
YOLO Deployment Options
- Local / On-Prem → Runs on PC/server.
Offline, private, low latency | Limited hardware, harder multi-user updates
Tools: Python API, ONNX Runtime - Edge Devices → Raspberry Pi, Jetson, Movidius.
Low power, IoT-ready | Limited compute → smaller models
Tools: TensorRT, Coral TPU SDK - Cloud API → Hosted, accessed via REST API.
Scalable, easy updates | Needs internet, privacy risks
Tools: AWS Lambda, GCP Run, FastAPI + Docker - Mobile / Embedded → Runs on Android/iOS.
Offline, camera integration, fast response | Hardware limits, larger app size
Tools: TFLite (Android), CoreML (iOS) - Web Apps → Browser-based dashboard/live detection.
No install, easy integration | Needs backend for heavy inference
Tools: FastAPI/Flask backend, React/Vue frontend, WebSockets for streaming
Personal Experiences working with YOLO
Ananth – worked with YOLO for model fine-tuning for the dress classifier use case.
They are :
1. Indian women’s Traditional dress classifier.
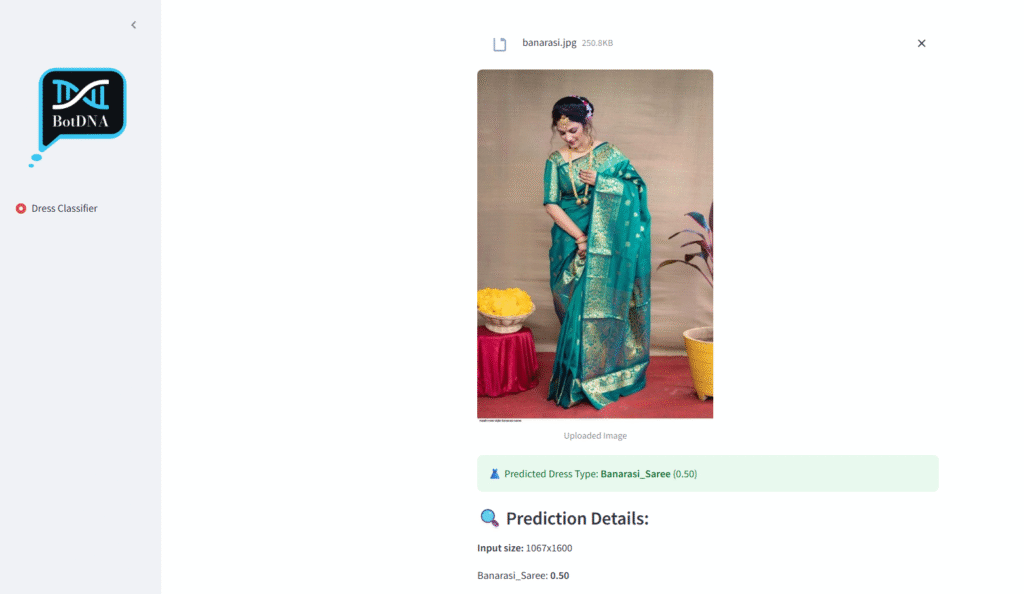
- He worked on an Indian women’s traditional dress classifier using a dataset from Roboflow.
- The major challenge was classifying sarees, as they vary widely in patterns, fabrics, and draping styles.
- These subtle differences made it difficult for the model to distinguish between saree types.
- Another limitation was the lack of sufficient and diverse saree images in the dataset.
- Training was also constrained since it was done on a CPU instead of GPU.
- As a result, the model reached about 80% accuracy, with clear room for improvement through more data and GPU training.
2. Number plate detector (commercial or private or ev)
- Transitioned from a traditional dress classification project to a number plate detection and classification system.
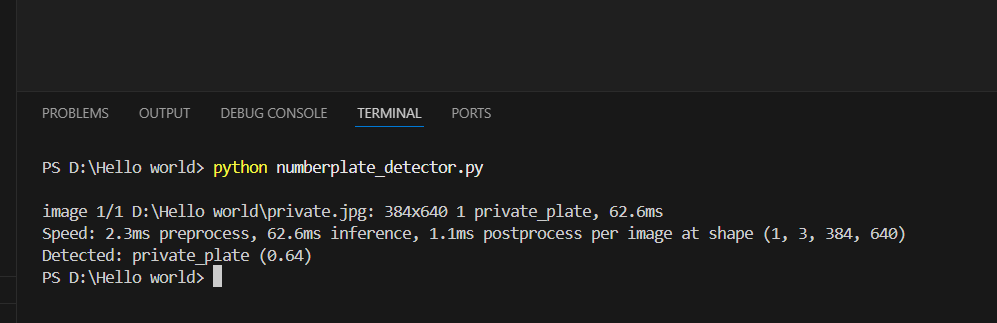
- The system detects number plates in images and classifies them by color: Commercial (yellow), Private (white), Electric Vehicle (green).
- Required a pre-annotated dataset with bounding boxes and class labels for training.
- Accurate annotations were critical for effective model learning.
- Initially trained the model for 25 epochs.
- Early results were poor; the model often failed to detect number plates.
- Increased training to 50 epochs to give the model more learning time.
- Performance improved significantly; the model detected and classified plates correctly 9 out of 10 times.
- Demonstrated the importance of sufficient training epochs for object detection tasks.
- Key takeaway: high-quality annotated data plus adequate training is essential for high detection accuracy.
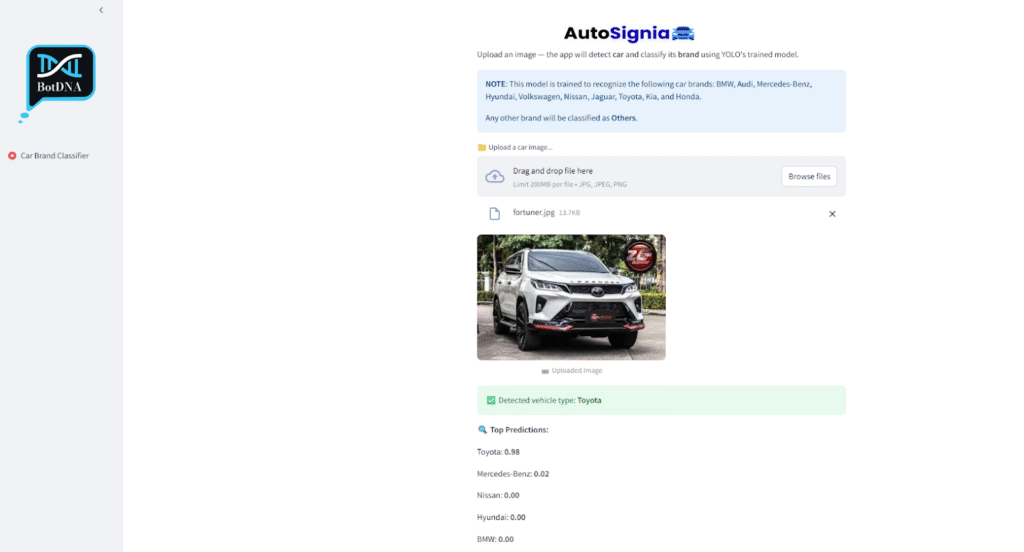
3. Car brand classifier.
- Moved on from number plate classification to classifying car brands (Mercedes, Audi, Jaguar, BMW, Toyota, etc.).
- Goal: upload a car image and identify its brand.
- Started with the yolov8n-cls model (smallest YOLO classification model).
- Used a Kaggle dataset with ~15–20 car brands, ~350 training images, ~100 test images, ~50 validation images.
- Initial training for 25 epochs gave poor results; the model misclassified non-car objects as cars.
- Implemented a two-phase approach: detection first (78 classes) to confirm if the image contains a car, then classification using a fine-tuned model for car brands. Non-car images are rejected in phase one.
- Encountered issues with SUVs, G-Wagon, and large vehicles being misclassified as trucks.
- Added 5 new car brands (Nissan, Honda, Kia, Volkswagen) and an “others” category for ambiguous vehicles; used detection-classification workflow to handle them.
- Fine-tuned the yolov8x-cls model for 80 epochs, achieving good results, though some errors remain inevitable.
- High predicted proportions of certain classes caused by repeated images in train/test/validation sets; ensuring distinct datasets improves prediction credibility and accuracy.

Options available for Model Fine Tuning without losing the previous classes
1. Full Fine-tuning with Old + New Data (Best but Costly)
- What: Retrain on both old dataset (80 classes) + your new dataset (sweet).
- Why: Prevents forgetting since the model continuously sees examples of old classes.
- How:
- Collect at least some representative samples of the original 80 classes.
- Merge them with your new sweet dataset.
- Train YOLO with all classes in the data.yaml file.
Limitation: Requires large storage and compute. On your system, you may need cloud GPU (e.g., Colab, Kaggle, or paid GPU service).
2. Incremental Learning via Knowledge Distillation
- What: Train the new model on the sweet class while forcing it to keep predictions of the old model.
- How:
- Use your original trained YOLO model as a teacher.
- During fine-tuning, minimize a loss between the new model’s predictions and the teacher’s predictions on old classes.
- Why: Keeps old knowledge alive.
- Tools: Some forks of YOLO and external repos support knowledge distillation for object detection.
3. Replay / Exemplar Method
- What: Save a small subset of old class samples (exemplars) and mix them with your new dataset.
- Why: Model “reminds” itself of old classes without retraining on the full dataset.
- Example: Keep ~100–500 images of each old class, and combine with your new dataset before fine-tuning.
4. Parameter Freezing
- What: Freeze earlier YOLO backbone layers (feature extractor) and fine-tune only the detection head on your new dataset.
- Why: Preserves low-level features useful for old classes.
- How:
In Ultralytics YOLO (PyTorch), you can freeze layers like:
model = YOLO(“yolov8n.pt”)
model.freeze(0,10) # Freeze first 10 layers
Limitation: Might reduce performance on the new class if data distribution is very different.
5. Use YOLO’s Built-in Transfer Learning
- YOLOv5/YOLOv8 supports resuming from pretrained weights and partial fine-tuning.
- You can specify a new data.yaml with all 81 classes (old + new), even if you don’t have full data for all old classes (paired with knowledge distillation/replay for stability).
6. Advanced Techniques
- Elastic Weight Consolidation (EWC): Regularizes weights important for old tasks so they don’t shift too much.
- Regularization-based continual learning: Add extra loss terms that penalize forgetting.
- YOLO-based continual learning frameworks: Search for YOLO incremental learning repos (e.g., YOLO-CL, YOLO-IL).